 17攻略
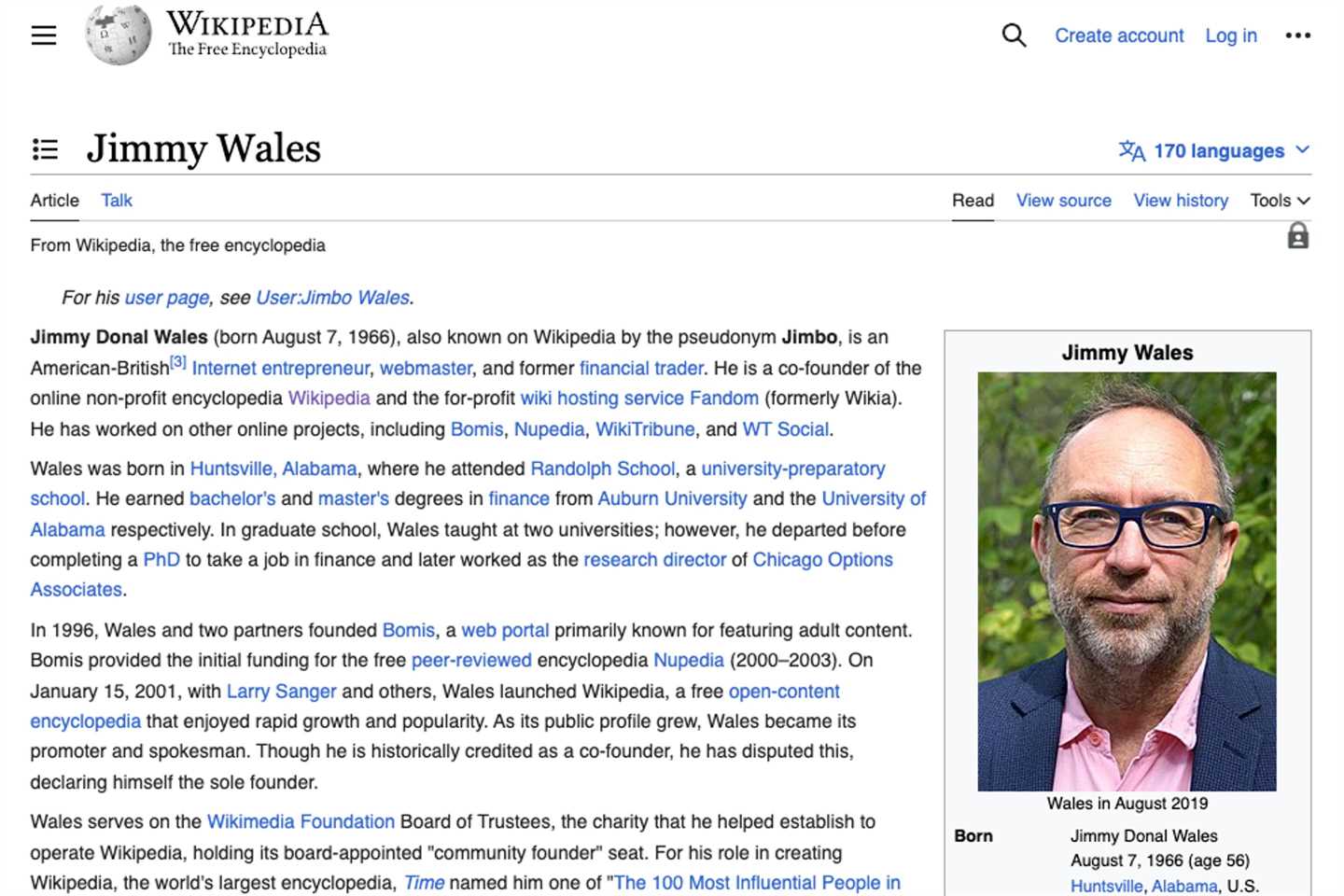
17攻略尽管GPT经常出现严重的信息不准确的状况,但它让维基百科的创始人吉米-威尔士认真思考人工智能如何成为人类历史上最大和最多读者的参考文献库的工作流程的一部分。在接受伦敦《标准晚报》的丹尼尔-汉伯瑞(Daniel Hambury)采访时,威尔士对该技术固有的一些问题进行了分析–特别是它的”胡言乱语”倾向,或者说是完全虚构的内容。
但他指出,”使用人工智能将维基百科的条目数量增加两倍,我们每年的运营成本不会增加超过1000英镑”。
威尔士说,一个早期的用例可能是使用像GPT这样的大型语言模型(LLM)来比较多篇文章,寻找相互矛盾的点,并利用其结果来识别维基百科的人类志愿者大军可能需要投入一些工作的内容。
“我认为我们离’ChatGPT,请写一个关于帝国大厦的维基百科条目’还有一段距离,”他告诉Hambury,”但我不知道我们离这有多远,当然比我两年前想的要近。”
一种可能的情况是,让人工智能去寻找维基百科上所有的许多空白–那些可能有用的页面从未被写过–并试图利用网络上的信息为它们创建摘要条目。
但威尔士意识到,维基百科的整个声誉是建立在对准确性的认知上的,而这是目前像GPT这样的法律硕士的一个巨大问题。他说:”它有一种凭空捏造东西的倾向,这对维基百科来说真的很糟糕。”那是不可以的。我们必须对此非常小心。”
如果让LLM编写像维基百科这样的中央知识库,那些没有被立即发现的幻觉或谎言在AI的放大作用下将开始像滚雪球一样越滚越大。人们会在自己的写作中使用这些非事实,随后的人工智能将被训练出这些非事实,从长远来看很难纠正它们,并容易使我们更深入地进入这个”后真相”时代。
威尔士还担心,使用LLM来扩展资源是否会帮助或加剧维基百科的系统性和无意识的偏见问题;该资源目前是由志愿者编写和维护的,其中绝大多数是白人男性,因此该网站倾向于忽略这一群体不感兴趣的话题,并从某种角度来报道其他话题。
ChatGPT的明确设计是为了在可能的情况下尝试从平衡的角度看待话题,试图将一些细微的差别带回讨论领域,在这些领域,来自不同方面的人越来越难以从任何共同点出发。但GPT在其训练数据中也有其固有的偏见问题。
这是一个棘手的问题,当然也会让赞助者考虑,如果该维基百科走这条路,是否还能继续捐款给它。但现实的是,任何组织如果不围绕下一代LLM的惊人能力重新定位,就会使自己在未来的竞争中处于巨大的劣势当中。







